Ejournals - system dostępu do czasopism elektronicznych
(opracowanie przygotowane w ramach realizacji zadań projektu KBN)
Tomasz Wolniewicz, UCI UMK, Toruń
Data opracowania: lipiec 2003
Założenia
Gwałtowne powiększanie się liczby czasopism dostępnych w formie elektronicznej tworzy bogactwo informacji dostępnej dla nauki. Nabywanie praw dostępu do czasopism przez konsorcja bibliotek powoduje, że większe uczelnie mają obecnie dostęp do pełnych tekstów 3-5 tysięcy czasopism i dodatkowo do abstraktów z kolejnych kilku tysięcy. Zarządzanie taką liczbą tytułów staje się złożonym zadaniem wymagającym zautomatyzowanych narzędzi.
Dostępne na rynku systemy komercyjne są wprawdzie wyposażone w bogactwo funkcji zarówno dla czytelnika jak i dla administratora, ale są również bardzo kosztowne. Okazuje się jednak, że te zaawansowane funkcje są używane stosunkowo rzadko, a większość czytelników korzysta wyłącznie z najprostszej możliwości jaką jest wyszukanie tytułu i skorzystanie z odsyłacza do zasobu elektronicznego.System o takiej funkcjonalności jest stosunkowo prosty do zaimplementowania przy pomocy publicznie dostępnych, bezpłatnych narzędzi. W niniejszym raporcie opisujemy system Ejournals, przygotowany w oparciu o bazę LDAP.
Przy budowie systemu wspomagającego dostęp do czasopism elektronicznych należało wziąć pod uwagę kilka elementów:
Prace przygotowawcze
Na podstawie rozmów z użytkownikami i bibliotekarzami oraz analizy podobnych rozwiązań w sieci ustalono, że interfejs powinien pozwalać na wyszukiwanie czasopisma po tytule i po nazwie wydawcy. Przy wyszukiwaniu po tytule najwłaściwszym wydaje się być dopasowanie dowolnego podciągu znaków. Dzięki temu w ramach jednego przeszukania można odnaleźć tytuły zawierające np. "networks" i "networking". Oczywiście w niektórych sytuacjach takie dopasowanie może być zbyt szerokie i dobrze byłoby gdyby użytkownik miał możliwość wprowadzenia ograniczeń, nie traktowano jednak tego priorytetowo. Przy wyszukiwaniu poprzez nazwę wydawcy powinno się dopasowywać całe słowa, bo w tym przypadku użytkownik zazwyczaj dokładnie wie czego szuka. Przeanalizowano zasadność wprowadzenia wyszukań ze względu na inne składniki opisu, np. numer ISSN. Taka potrzeba niewątpliwie istnieje w interfejsie administratora systemu, ale wątpliwe jest by ta funkcja była przydatna w zwykłym interfejsie użytkowym.
Implementacja
System Ejournals został przygotowany w oparciu o bazę LDAP i specjalnie zaprojektowany schemat. Za użyciem właśnie tej bazy przemawiał zakładany sposób dostępu do danych czyli prawie wyłącznie operacje odczytu, ponadto system musiał zapewniać skalowalność bazy do dużej liczby wpisów, prostotę połączenia bazy z narzędziami projektowania systemów WWW i łatwość oddzielenia systemu bazy danych od systemu interfejsu użytkownika.
Interfejs użytkownika i administratora napisano w języku PHP. Uzupełniające oprogramowanie zapewniające synchronizację zawartości w języku Perl. Te języki skryptowe są wyposażone w narzędzia komunikacji z bazą LDAP.
Opracowano schemat bazy poprzez dodanie jednej klasy obiektów o następujących atrybutach:
Kompletny schemat, w formacie akceptowanym przez system OpenLDAP, jest przytoczony z Załączniku 1.
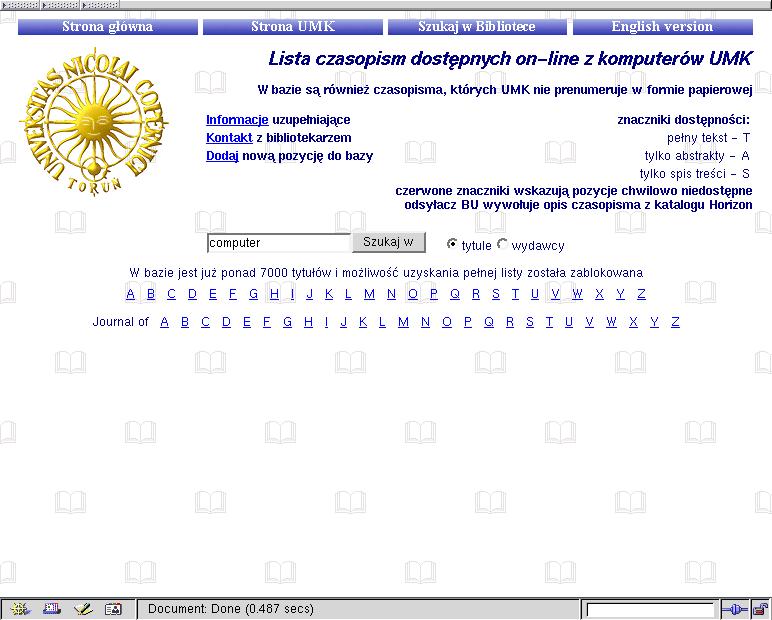
Czytelnik może przeszukiwać bazę ze względu na ciąg znaków zawarty w tytule lub słowo z nazwy wydawcy. Ponadto dostępne są listy czasopism, których tytuły zaczynają się od wybranej litery, i podlisty typu "Journal of x" gdzie x jest początkową literą dalszej części nazwy.
.
Ekran początkowy
Wyniki przeszukania przedstawiane są w postaci tabeli, której wiesze zawierają: tytuł czasopisma, będący jednocześnie odsyłaczem do zasobu elektronicznego, nazwę wydawcy, znacznik określający rodzaj dostęepu (T - pełny tekst, A - tylko streszczenia, S - tylko spis treści) oraz opcjonalny znacznik możliwości odwołania do katalogu biblioteki (znacznik BU).

Wynik przeszukania
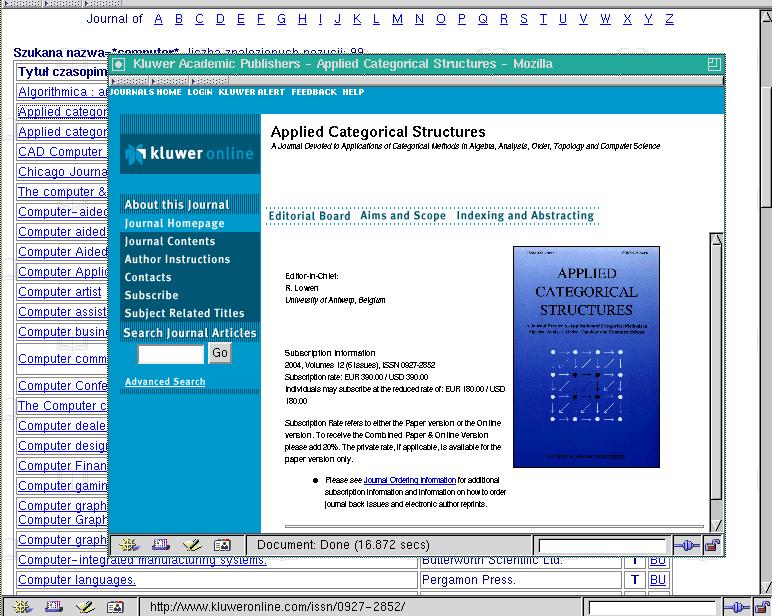
Wywołanie strony czasopisma
Jeżeli czasopismo posiada opis w katalogu bibliotecznym, to do tej informacji można bardzo prosto dotrzeć poprzez znacznik BU.
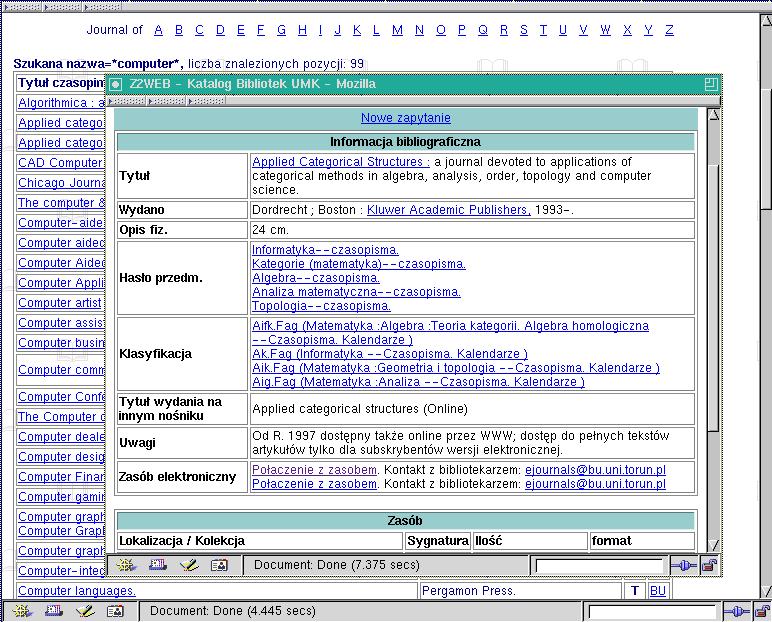
Wywołanie opisu z katalogu biblioteki
Czytelnicy mogą samodzielnie tworzyć nowe wpisy. Trafiają one bezpośrednio do bazy, ale ze specjalnym statusem. Dzięki temu są widoczne tylko w interfejsie administratora i dopiero po zatwierdzeniu stają się dostępne dla wszystkich.

Formularz dodania nowej pozycji
Raz na dobę sprawdza się dostępność odsyłaczy występujących w bazie. Odsyłacze do serwerów, na których przechowywane są bazy wielu czasopism są traktowane specjalnie, aby nie przeciążać tych serwerów wielokrotnymi połączeniami. Wpisy niedostępne w momencie sprawdzenia są zaznaczane jako "chwilowo niedostępne", a następnie kontrolowane co godzinę. Jeżeli problemy z dostępem nie ustępują przez dwie doby, to tytuł jest zaznaczany jako błędny i zdejmowany z listy widzianej przez użytkownika.
Zadaniem administratora systemu Ejournal jest kontrolowanie wpisów o specjalnych statusach (nowo zgłoszonych oraz błędnych) i dopisywanie nowych pozycji.
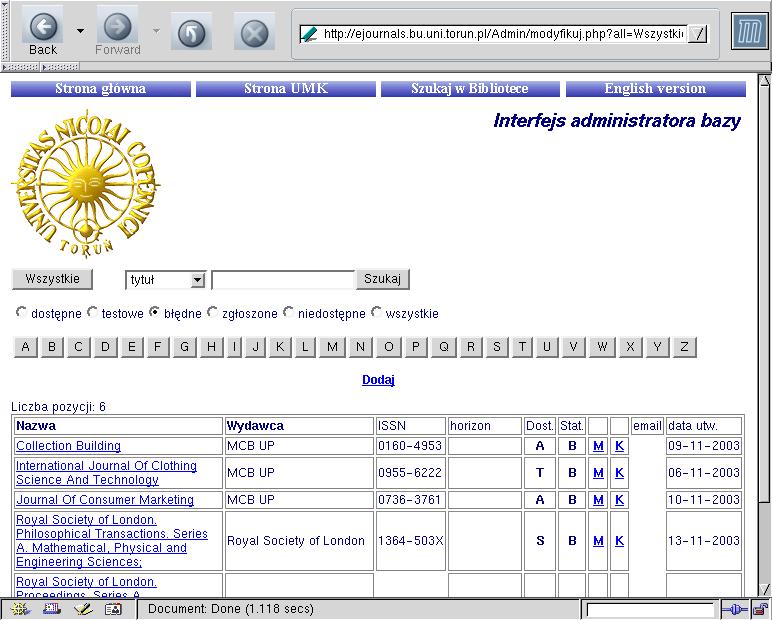
Interfejs administratora
Synchronizacja z katalogiem czasopism
W Polsce o lat prowadzi się ogólnopolską akcję katalogowania czasopism naukowych w ramach centralnego katalogu czasopism (początkowo CKTCz, obecnie fragment NUKat). Jednym z elementów opisu bibliograficznego może być odsyłacz do zasobu elektronicznego. Każdy opis ma jednoznaczny identyfikator. W ramach systemu Ejournal stworzono mechanizmy probiernia i synchronizacji danych z systemu katalogowego. Synchronizacja odbywa się z użyciem pośredniego pliku tekstowego, co uniezależnia mechanizm od konkretnego systemu bibliotecznego. Raz na dobę z systemu bibliotecznego jest generowany plik zawierający rekordy nowe oraz zmodyfikowane. Oprogramowanie napisane w języku Perl sprawdza czy baza Ejournals zawiera wpisy o numerach identyfikacyjnych zgodnych z nadesłanymi w poprawkach. Odnalezione wpisy są kasowane, a następnie cała zawartość pliku poprawek jest dopisywana do bazy Ejournals.
Wdrożenie
System Ejournals został wdrożony na UMK w styczniu 2003 r. Na wstępie załadowano do niego około 3 tys. rekordów (wszystkie występujące w katalogu komputerowym UMK opisy czasopism zawierające informację o zasobie elektronicznym). Pomimo, że w tym momencie system Ejournals zawierał identyczną informację jak katalog biblioteczny, to dedykowany interfejs i łatwość jego obsługi sprawiły, że czytelnicy wykazali duże zainteresowanie. W kolejnych krokach załadowano listę czasopism matematycznych pobraną z AMS, a następnie zestawy danych uzyskane od dużych wydawców. W niektórych przypadkach niezbędna była ręczna weryfikacja odsyłaczy elektronicznych oraz określenie sposobu dostępu. Obecnie baza Ejournals zawiera ponad 7 tys. wpisów.
System Ejournals został zaprojektowany z myślą o pojedynczej uczelni, tym niemniej od momentu uruchomienia spotkał się ze znaczącym zainteresowaniem wielu bibliotek w Polsce. Dozwolony sposób dostępu do czasopisma (pełny tekst, abstrakty lub spisy treści) zależy od licencji wykupionych przez konkretną uczelnię, a zatem opis odpowiadający sytuacji UMK może być nieprawidłowy, gdy do informacji odwołuje się pracownik innej uczelni, ale w praktyce rozbieżności nie są duże, bo wiele uczelni należy to tych samych konsorcjów co UMK i w konsekwencji ma identyczne prawa dostępu do poszczególnych tytułów.
System może być łatwo zainstalowany w innych bibliotekach, lokalni administratorzy musieliby jednak samodzielnie sprawdzić prawidłowość określenia sposobu dostępu.
W poniższej tabeli przedstawiono liczby dostępów do bazy w ciągu października 2003.
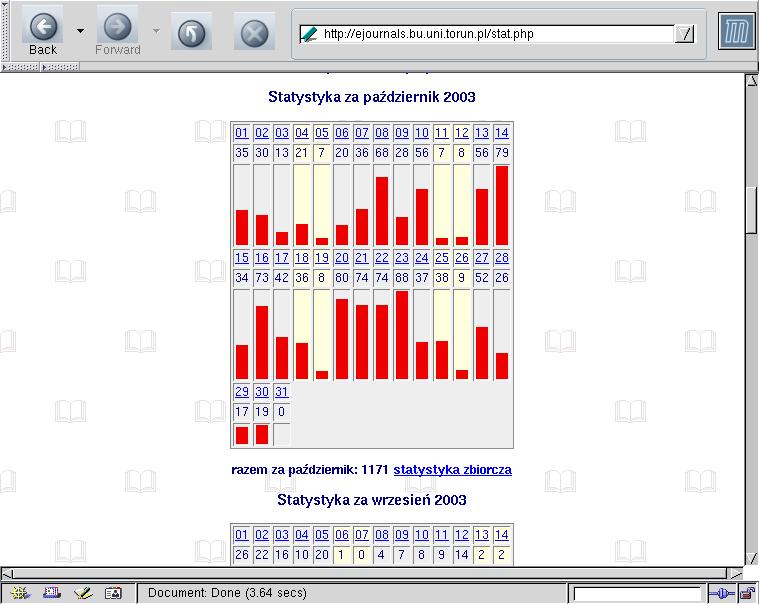
Statystyka
Schemat bazy
attributetype ( 1.3.6.1.4.1.13685.3.5.1
NAME 'publisher'
DESC 'Wydawca'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.2
NAME 'ISSN'
DESC 'ISSN'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.3
NAME 'horizonControlNo'
DESC 'numer kontorlny w bazie Horizon'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.4
NAME 'accessForm'
DESC 'format dostepu - text,abstract,spis'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.5
NAME 'jId'
DESC 'identyfikator jednoznaczny entry'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.6
NAME 'recId'
DESC 'identyfikator jednoznaczny rekordu bibl.'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.7
NAME 'processedName'
DESC 'przetworzony tytul dla sortowania'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.8
NAME 'recStatus'
DESC 'status rekordu'
EQUALITY integerMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27
)
attributetype ( 1.3.6.1.4.1.13685.3.5.9
NAME 'secRecId'
DESC 'identyfikator ponownego wystapienia rekordu bibl.'
SUP name
)
attributetype ( 1.3.6.1.4.1.13685.3.5.10
NAME 'unavailCount'
DESC 'ile razy niedostepne'
EQUALITY integerMatch
SYNTAX 1.3.6.1.4.1.1466.115.121.1.27
)
objectclass ( 1.3.6.1.4.1.13685.3.6.1
NAME 'ejournal'
SUP top
MUST (
jId $
cn $
processedname $
publisher $
labeledURI
)
MAY (
ISSN $
accessForm $
mail $
recstatus $
recid $
secrecid $
unavailCount $
horizonControlNo )
)